Light-weight real-time event detection with Python
Carson J. Q. Farmer
@carsonfarmer
carsonfarmer.com
carsonfarmer@gmail.com
github.com/cfarmer
Hunter College, City University of New York
695 Park Ave, New York, NY, 10065
Social information sources

Source: Digiself

Streaming framework
Source: Digiself
So what are we doing?
- Stream Twitter data (location-based)
- Online Latent Semantic Analysis
- Gridded count of geo-tweets
- Kernel density estimation (KDE)
- Normalize tweet density
- Identify high density areas
- Feedback results
- tweepy
- gensim
- python-geohash
- scipy/numpy (fast_kde.py)
- numpy
- numpy
- pico+leaflet+D3js
Twitter part is easy
import tweepy
import simplejson
import sys
consumer_key = ''
consumer_secret = ''
access_token_key = ''
access_token_secret = ''
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token_key, access_token_secret)
BOUNDING_BOX = [xmin, ymin, xmax, ymax]
class CustomStreamListener(tweepy.StreamListener):
def on_status(self, tweet):
print('Ran on_status')
def on_error(self, status_code):
print('Error: ' + repr(status_code))
return True # Don't die!
def on_data(self, data):
document = simplejson.loads(data)
# Do something awesome with the tweet info...
sapi = tweepy.streaming.Stream(auth, CustomStreamListener())
sapi.filter(locations=BOUNDING_BOX)
LSA part isn't easy
- Latent Semantic Analysis
- Analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms
- Idea is that words that are close in meaning will occur in similar pieces of text
- Latent Semantic Indexing (LSI)
- Tokenizing (
ark-twokenize-py), remove common and unique words (stopwords.py)- Twitter NLP and Part-of-Speech Tagging
- Snowball String Processing Language
- Bag-of-words, and/or tf–idf (term frequency–inverse document frequency)
- Decay < 1.0 to favor new data trends in input stream
- Possibly try Hierarchical Dirichlet Process (because we don't have to pick # of topics [and gensim has it])
Gridded topic counts
- Geohash all coordinates to given scale (optimize for urban environment)
- Convert back to x, y coords (now gridded)
- Count unique tweets of given topic
- Normalize counts (by current count and tweet 'population'
Online (kinda) KDE
- Gaussian kernel density estimate
- Convolution of Gaussian kernel with the 2D histogram
- Typically several orders of magnitude faster than
scipy.stats.kde.gaussian_kdefor large (>1e7) numbers of points- Can handle ~billion points already without too much trouble…
- Streaming framework
- Stream 2D histogram binning process
- Run convolution on this when needed
- Supports weighted KDE
- Take topic component weights when computing KDE
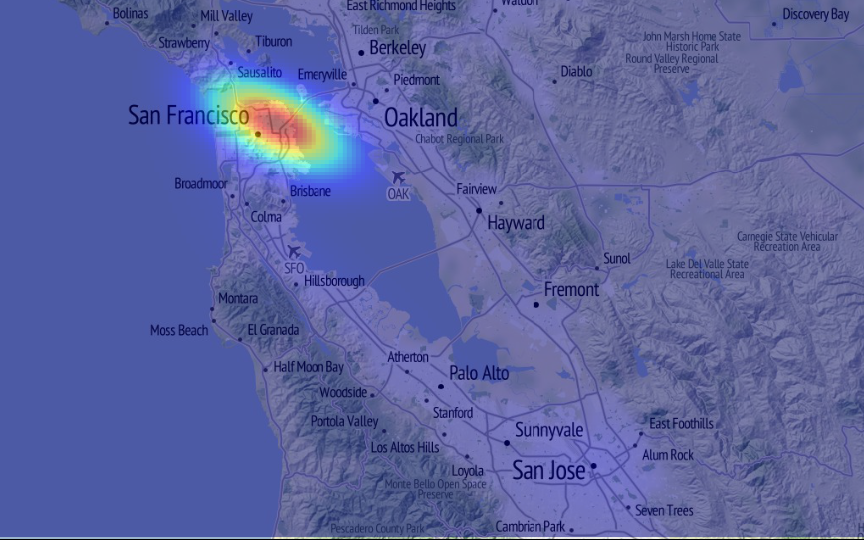
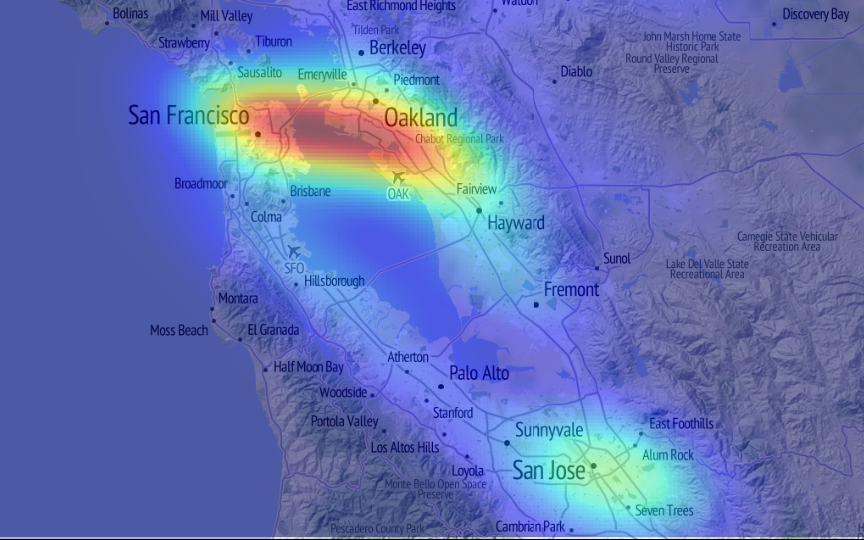
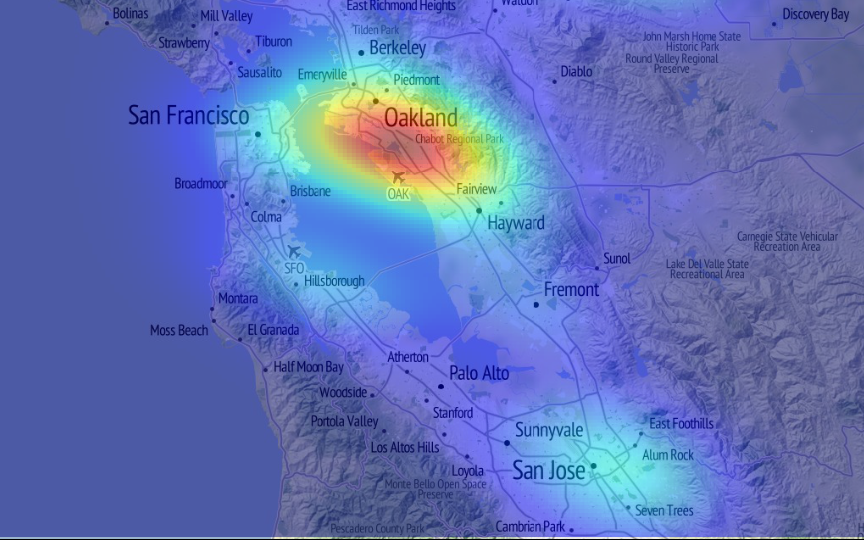
Identify 'events'
- Locate high-density areas
- Right now…
- Let 'user' browse current topics & select for viewing
- Eventually more automation
- Have to get scale right…
- We're focusing on urban areas (city scale)
#batkid
concert
#drake
Feedback results
Pico- very small web application framework forPython- Bridge between server side
Pythonand client sideJavascript
- Bridge between server side
Picois a server, aPythonlibary and aJavascriptlibrary!- Server is a WSGI application
Picoallows you to stream data fromPythontoJavascript- Simply write your function as a
Pythongenerator!
- Simply write your function as a
Write a Python module
# example.py
import pico
def hello(name="World"):
return "Hello " + name
Start the server
python -m pico.server
Call your Python functions from Javascript
<!DOCTYPE HTML>
<html>
<head>
<title>Pico Example</title>
<script src="/pico/client.js"></script>
<script>
pico.load("example");
</script>
</head>
<body>
<p id="message"></p>
<script>
example.hello("Fergal", function(response){
document.getElementById('message').innerHTML = response;
});
</script>
</body>
</html>
Want that to stream?
import pico
import gevent
@pico.stream
def stream():
for line in open('long_file.txt'):
yield line
gevent.sleep(0.1)
(Plus some other gevent magic)
'Normal' call from Javascript
example.stream(function(line){
console.log(line)
})
Where are we at now?
- Code and 'science' works for the most part
- Nowhere near 'production' ready
- Web-framework is non-existant (but getting ready)
- My collaborator (
picoauthor) just got a 'real-job' and got married
- My collaborator (
- Very happy with how lightweight and 'easy' this is to setup
- You can pretty much just drop
anacondaor similar on a server and this will work
- You can pretty much just drop
What did we learn?
- Twitter had the x and y coordinates reversed for a while :-p
- People talk about themselves a lot!
- Most tweets at least contain
i'm,my,me, etc… - Stopwords and good tokenizing are important!
- Most tweets at least contain
- English language is often ambiguous
- (i.e., this stuff is hard)
- Geography is still important
- Many tweets have spatial component and twitter trends do vary geographically
#batkid versus everything
Light-weight real-time event detection with Python
Carson J. Q. Farmer
@carsonfarmer
carsonfarmer.com
carsonfarmer@gmail.com
github.com/cfarmer
Hunter College, City University of New York
695 Park Ave, New York, NY, 10065